レクチャーはすべて英語ですが、字幕も表示できるのでそれで補足しながらであれば説明されていることは概ね把握できますし、スライドや PC の画面も表示されるので理解の助けになります。かつ、この CS50 の担当教授である David J. Malan 先生の熱量がすごく、たとえば生徒も巻き込んでステージ上でアルゴリズムのイメージを実演してくれるなどしながら、毎回非常にわかりやすく講義内容を説明してくれます。ただし私のように非ネイティブの人にとっては、この人の喋りは勢いがすごくかなり早口に感じると思うので、最初それについていくのが大変かもしれません。
各講義回ごとに演習用の課題が用意されており、実際に課題の要件を満たすプログラムを実装して提出する必要があるのもやっていて楽しい点です。 CS50 では Cloud9 をベースにした CS50 IDE という Web IDE が提供されていて、ブラウザ上でコーディングから課題の提出までおこなえるので、ローカルに開発環境を構築する手間がまったく必要ないのもいいところです。実装結果を提出するとリモートでテストが実行され、要件を満たしているかどうか自動的に評価されるようになっていて、これも素晴らしい点だと思います。
ただし Cloud9 のサーバーがおそらく米国にあるため、日本から使うと IDE のターミナル上でのコマンドの入力に微妙に遅延を感じます (遠い国にあるサーバーに SSH して操作するときに感じるラグと同じ感じ)。なお IDE エディタ上のコーティング作業自体はまったく問題ありません。
Week 1 ~ 4 の講義の内容と学んだこと
コンピュータサイエンスの入門講座のため、とても基礎的な内容ですが、私にとっては良い勉強になりました。特に探索やソートといったアルゴリズムや、 C 言語のメモリ管理、そしてデータ構造の実装について実際に手を動かして学ぶことができました。
Week 3 ではメモリ管理やポインタが主題でした。私がよく使う Go 言語だとありがたいことに GC とエスケープ解析があるので、通常各ポインタのオブジェクトがスタックとヒープのどちらに置かれているか意識しないで済んでしまいます。一方 C 言語ではプログラマがちゃんと考えて、スタックにアロケートするかヒープにアロケートするか判断する必要があります。このように自力でメモリ管理をするプログラムを書く経験もやはり大事だなと感じました。
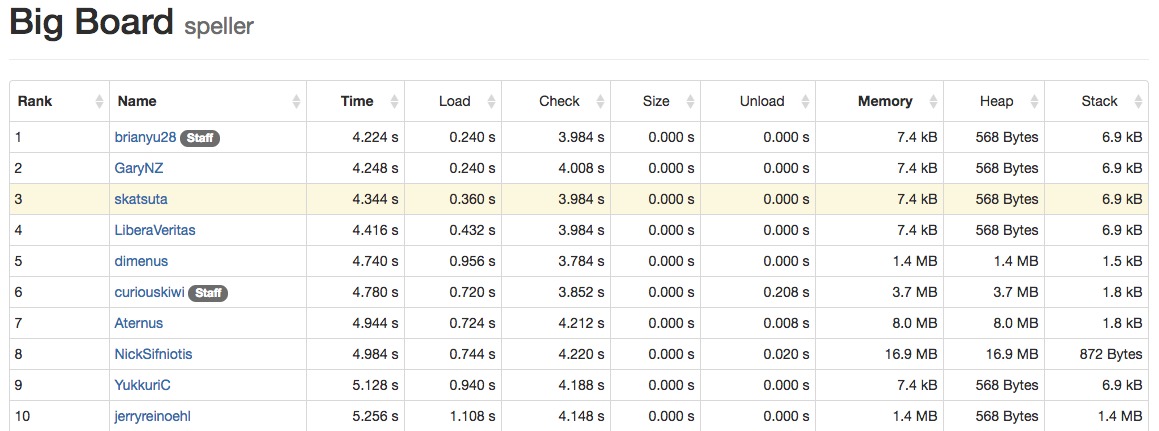
実際のところ私よりも上位のランカーがまだいるわけなので、まだ最適化の余地は残されているんだろうとは思っていますが、今の私の知識や技術ではこれ以上の改善は難しい状況なので、いつかまた修行を積んでから再度挑戦できたらいいなと思います。このランキングの参加者は基本的に初学者のはずで、演習課題の実装内容自体も簡素なものなので、おそらく速度に気を使って C / C++ 言語を長い間書いてきたプログラマの方であれば、私よりも全然速いプログラムを書ける可能性がかなり高いと思っています。なのでもしこの記事を読んで興味が沸いた方は、この演習だけでもやってみるとおもしろいかもしれません。
あと個人的に良かった副作用として、 C 言語が結構好きになりました。日頃現代的な言語を使っていると古臭い言語に感じることは確かで、実際不便な点やバグを生みやすい点も数多くありますが、この素朴さは特に低レイヤのプログラムを書くのにはやっぱり使いやすいんだろうなと思います。今となっては C でも Go でも問題なくポインタを扱うことができるようになっていますが、実は昔 C のポインタで一度挫折した経験があったので、それを無事克服することができてよかったです。
type BlockMode interface { // BlockSize returns the mode's block size. BlockSize() int
// CryptBlocks encrypts or decrypts a number of blocks. The length of // src must be a multiple of the block size. Dst and src may point to // the same memory. CryptBlocks(dst, src []byte) }
// NewCBCEncrypter returns a BlockMode which encrypts in cipher block chaining // mode, using the given Block. The length of iv must be the same as the // Block's block size. funcNewCBCEncrypter(b Block, iv []byte)BlockMode { iflen(iv) != b.BlockSize() { panic("cipher.NewCBCEncrypter: IV length must equal block size") } return (*cbcEncrypter)(newCBC(b, iv)) }
func(x *cbcEncrypter)CryptBlocks(dst, src []byte) { iflen(src)%x.blockSize != 0 { panic("crypto/cipher: input not full blocks") } iflen(dst) < len(src) { panic("crypto/cipher: output smaller than input") }
iv := x.iv
forlen(src) > 0 { // Write the xor to dst, then encrypt in place. xorBytes(dst[:x.blockSize], src[:x.blockSize], iv) x.b.Encrypt(dst[:x.blockSize], dst[:x.blockSize])
// Move to the next block with this block as the next iv. iv = dst[:x.blockSize] src = src[x.blockSize:] dst = dst[x.blockSize:] }
// Save the iv for the next CryptBlocks call. copy(x.iv, iv) }
// NewCBCDecrypter returns a BlockMode which decrypts in cipher block chaining // mode, using the given Block. The length of iv must be the same as the // Block's block size and must match the iv used to encrypt the data. funcNewCBCDecrypter(b Block, iv []byte)BlockMode { iflen(iv) != b.BlockSize() { panic("cipher.NewCBCDecrypter: IV length must equal block size") } return (*cbcDecrypter)(newCBC(b, iv)) }
続いて cbcDecrypter の CryptBlocks() メソッドの実装を見てみます。 To avoid making a copy each time, we loop over the blocks BACKWARDS. というコメントがある通り、復号処理は暗号文の末尾から逆順でおこなっているようです。しかしながら、「コピーを防ぐため」ということの意図はよくわかりませんでした。
// For each block, we need to xor the decrypted data with the previous block's ciphertext (the iv). // To avoid making a copy each time, we loop over the blocks BACKWARDS. end := len(src) start := end - x.blockSize prev := start - x.blockSize
// Copy the last block of ciphertext in preparation as the new iv. copy(x.tmp, src[start:end])
// Loop over all but the first block. for start > 0 { x.b.Decrypt(dst[start:end], src[start:end]) xorBytes(dst[start:end], dst[start:end], src[prev:start])
end = start start = prev prev -= x.blockSize }
// The first block is special because it uses the saved iv. x.b.Decrypt(dst[start:end], src[start:end]) xorBytes(dst[start:end], dst[start:end], x.iv)
// Set the new iv to the first block we copied earlier. x.iv, x.tmp = x.tmp, x.iv }
// NewCipher creates and returns a new cipher.Block. // The key argument should be the AES key, // either 16, 24, or 32 bytes to select // AES-128, AES-192, or AES-256. funcNewCipher(key []byte)(cipher.Block, error) { k := len(key) switch k { default: returnnil, KeySizeError(k) case16, 24, 32: break }
n := k + 28 c := &aesCipher{make([]uint32, n), make([]uint32, n)} expandKey(key, c.enc, c.dec) return c, nil }
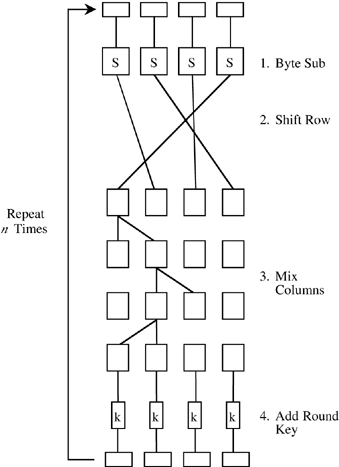
ラウンド鍵を生成する expandKey() の処理を見てみましょう。実は Go における AES の処理は CPU アーキテクチャが AMD64 か否かで分岐しています。 AMD64 の場合には以下のように、アセンブリコードがある場合にはそちらを使用するようになっており、ソースコードには asm_amd64.s というアセンブリも一緒に含まれています。高速に AES の処理をおこなうための工夫でしょう。
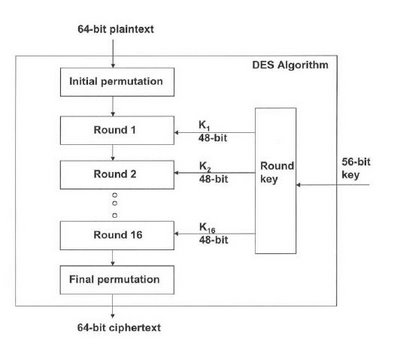
ではまず実際に DES で暗号化/復号をおこなってみます。 DES 用のオブジェクトは crypto/des パッケージの NewCipher() で生成します。戻り値は cipher.Block インターフェースで、この Encrypt()/Decrypt() メソッドはそれぞれ DES による暗号化と復号の処理を実装しています。
// Encrypt one block from src into dst, using the subkeys. funcencryptBlock(subkeys []uint64, dst, src []byte) { cryptBlock(subkeys, dst, src, false) }
// Decrypt one block from src into dst, using the subkeys. funcdecryptBlock(subkeys []uint64, dst, src []byte) { cryptBlock(subkeys, dst, src, true) }
funccryptBlock(subkeys []uint64, dst, src []byte, decrypt bool) { b := binary.BigEndian.Uint64(src) b = permuteInitialBlock(b) left, right := uint32(b>>32), uint32(b)
var subkey uint64 for i := 0; i < 16; i++ { if decrypt { subkey = subkeys[15-i] } else { subkey = subkeys[i] }
left, right = right, left^feistel(right, subkey) } // switch left & right and perform final permutation preOutput := (uint64(right) << 32) | uint64(left) binary.BigEndian.PutUint64(dst, permuteFinalBlock(preOutput)) }
ラウンド関数 $f$ の実装は feistel() という関数ですが今回は割愛します。
Triple DES (3DES)
Triple DES とは
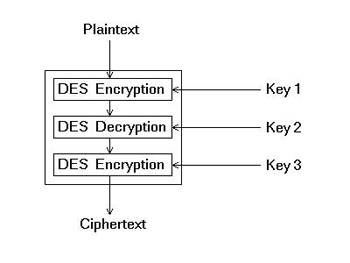
Triple DES (3DES) は、 DES よりも強力になるよう、 DES を3段重ねにした暗号アルゴリズムです。 Triple DES は TLS でも使われています。ただし、 AES (Advanced Encryption Standard) がある今、あえて Triple DES を使う必然性は薄いです。
Triple DES の特徴は、暗号化を3回おこなうのではなく【暗号化 → 復号化 → 暗号化】という重ね方をするところです。これは、すべての鍵を等しくすれば単なる DES と同じように使えるように互換性が確保されているためです。
一方、ポインタ型に対してあるメソッドが定義されているときに、値型変数からそのメソッドを呼び出そうとすると、コンパイラが暗黙的にポインタ型のメソッド呼び出しに変換してくれます。以下の例では、 ポインタ型 *Person に Shout() が定義されていますが、 Person 型変数 p からでも問題なく呼び出せます。
// n: メソッドを表す AST ノード // t: メソッドをもつ型を表す AST ノード funcmethodname1(n *Node, t *Node) *Node { star := "" if t.Op == OIND { star = "*" t = t.Left }
if t.Sym == nil || isblank(n) { return newfuncname(n.Sym) }
var p string if star != "" { p = fmt.Sprintf("(%s%v).%v", star, t.Sym, n.Sym) // (*Type).Method } else { p = fmt.Sprintf("%v.%v", t.Sym, n.Sym) // Type.Method }
if exportname(t.Sym.Name) { n = newfuncname(Lookup(p)) } else { n = newfuncname(Pkglookup(p, t.Sym.Pkg)) }
return n }
上記コードの変数 p を見ていただくとわかる通り、メソッド定義においてメソッド名は (*Type).Method または Type.Method という名前をもつ、関数の AST ノードに変換されています。
フィールドがプライベートなので直接の値の変更ができず、またレシーバも戻り値もほぼすべてポインタ型ではなく値型なので、一度生成された Time オブジェクトは一切変更する手段がないということになります。
Java では java.util.Date クラスや java.util.Calendar クラスが可変でスレッドセーフではないことが長年問題となっており、やっと Java 8 で不変オブジェクトを基本とする java.time パッケージが導入されました(Java SE 8 Date and Time -新しい日付/時間ライブラリが必要になる理由-)。 Go では少なくともこの種の問題は避けられているわけですね。
それでも Go ではエクスポートされたフィールドの直接書き換えや、オブジェクトの内部状態を書き換える副作用のあるメソッドが気軽に用いられる傾向にあります。並行処理に耐える不変オブジェクトを設計したい場合は、 Time を参考にした構造体設計にするとよいかもしれません。
# ホスト一覧を表示する $ docker-machine ls NAME ACTIVE DRIVER STATE URL SWARM default - virtualbox Running tcp://192.168.99.121:2376 demo * virtualbox Running tcp://192.168.99.118:2376 dev - virtualbox Stopped
# default が active になった $ docker-machine ls NAME ACTIVE DRIVER STATE URL SWARM default * virtualbox Running tcp://192.168.99.121:2376 demo - virtualbox Running tcp://192.168.99.118:2376 dev - virtualbox Stopped
# default にある image は ubuntu $ docker images REPOSITORY TAG IMAGE ID CREATED VIRTUAL SIZE ubuntu latest e9ae3c220b23 4 days ago 187.9 MB
# 削除も簡単 $ docker-machine rm stg $ docker-machine ls NAME ACTIVE DRIVER STATE URL SWARM demo * virtualbox Running tcp://192.168.99.100:2376 dev - virtualbox Running tcp://192.168.99.102:2376
$ docker-machine-driver-virtualbox This is a Docker Machine plugin binary. Plugin binaries are not intended to be invoked directly. Please use this plugin through the main 'docker-machine' binary.
// サーバのバージョンを確認する var version int if err := c.Client.Call("RpcServerDriver.GetVersion", struct{}{}, &version); err != nil { returnnil, err } log.Debug("Using API Version ", version)
funcRegisterDriver(d drivers.Driver) { // $MACHINE_PLUGIN_TOKEN != 42 の場合は終了する if os.Getenv(localbinary.PluginEnvKey) != localbinary.PluginEnvVal { fmt.Fprintln(os.Stderr, `This is a Docker Machine plugin binary. Plugin binaries are not intended to be invoked directly. Please use this plugin through the main 'docker-machine' binary.`) os.Exit(1) }
// Driver defines how a host is created and controlled. Different types of // driver represent different ways hosts can be created (e.g. different // hypervisors, different cloud providers) type Driver interface { // Create a host using the driver's config Create() error
// DriverName returns the name of the driver as it is registered DriverName() string
// GetCreateFlags returns the mcnflag.Flag slice representing the flags // that can be set, their descriptions and defaults. GetCreateFlags() []mcnflag.Flag
// GetIP returns an IP or hostname that this host is available at // e.g. 1.2.3.4 or docker-host-d60b70a14d3a.cloudapp.net GetIP() (string, error)
// GetMachineName returns the name of the machine GetMachineName() string
// GetSSHHostname returns hostname for use with ssh GetSSHHostname() (string, error)
// GetSSHKeyPath returns key path for use with ssh GetSSHKeyPath() string
// GetSSHPort returns port for use with ssh GetSSHPort() (int, error)
// GetSSHUsername returns username for use with ssh GetSSHUsername() string
// GetURL returns a Docker compatible host URL for connecting to this host // e.g. tcp://1.2.3.4:2376 GetURL() (string, error)
// GetState returns the state that the host is in (running, stopped, etc) GetState() (state.State, error)
// Kill stops a host forcefully Kill() error
// PreCreateCheck allows for pre-create operations to make sure a driver is ready for creation PreCreateCheck() error
// Remove a host Remove() error
// Restart a host. This may just call Stop(); Start() if the provider does not // have any special restart behaviour. Restart() error
// SetConfigFromFlags configures the driver with the object that was returned // by RegisterCreateFlags SetConfigFromFlags(opts DriverOptions) error
// CPU レベルでの仮想化機能が有効化チェックする if d.IsVTXDisabled() { // Let's log a warning to warn the user. When the vm is started, logs // will be checked for an error anyway. // We could fail right here but the method to check didn't prove being // bulletproof. log.Warn("This computer doesn't have VT-X/AMD-v enabled. Enabling it in the BIOS is mandatory.") }
log.Infof("Creating VirtualBox VM...")
// import b2d VM if requested if d.Boot2DockerImportVM != "" { name := d.Boot2DockerImportVM
// make sure vm is stopped _ = d.vbm("controlvm", name, "poweroff")
// let VBoxService do nice magic automounting (when it's used) if err := d.vbm("guestproperty", "set", d.MachineName, "/VirtualBox/GuestAdd/SharedFolders/MountPrefix", "/"); err != nil { return err } if err := d.vbm("guestproperty", "set", d.MachineName, "/VirtualBox/GuestAdd/SharedFolders/MountDir", "/"); err != nil { return err }
// 共有ディレクトリ名を設定する var shareName, shareDir string// TODO configurable at some point switch runtime.GOOS { case"windows": shareName = "c/Users" shareDir = "c:\\Users" case"darwin": shareName = "Users" shareDir = "/Users" // TODO "linux" }
// 共有ディレクトリをマウントする if shareDir != "" && !d.NoShare { log.Debugf("setting up shareDir") if _, err := os.Stat(shareDir); err != nil && !os.IsNotExist(err) { return err } elseif !os.IsNotExist(err) { if shareName == "" { // parts of the VBox internal code are buggy with share names that start with "/" shareName = strings.TrimLeft(shareDir, "/") // TODO do some basic Windows -> MSYS path conversion // ie, s!^([a-z]+):[/\\]+!\1/!; s!\\!/!g }
In the application, each record will have a key associated with it. This key is what the application will use to read or write the record.
However, when the key is sent to the database, the key (together with the set information) is hashed into a 160-bit digest. Within the database, the digest is used address the record for all operations.
The key is used primarily in the application, while the digest is primarily used for addressing the record in the database.
The key maybe either an Integer, String, or Bytes value.n
$ go run main.go aerospike.Record{Key:(*aerospike.Key)(0xc8200da000), Node:(*aerospike.Node)(0xc8200ae000), Bins:aerospike.BinMap{"a":"abc", "b":123}, Generation:1, Expiration:432000}
$ aql aql> SELECT * FROM test.testset +-------+-------+-----+ | key | a | b | +-------+-------+-----+ | "xyz" | "abc" | 123 | +-------+-------+-----+ 1 row inset (0.055 secs)
$ gem install sqlite3 -v '1.3.10' Building native extensions. This could take a while... ERROR: Error installing sqlite3: ERROR: Failed to build gem native extension.
/Users/skatsuta/.rbenv/versions/2.1.5/bin/ruby extconf.rb checking for sqlite3.h... *** extconf.rb failed *** Could not create Makefile due to some reason, probably lack of necessary libraries and/or headers. Check the mkmf.log file for more details. You may need configuration options.
Provided configuration options: --with-opt-dir --without-opt-dir --with-opt-include --without-opt-include=${opt-dir}/include --with-opt-lib --without-opt-lib=${opt-dir}/lib --with-make-prog --without-make-prog --srcdir=. --curdir --ruby=/Users/skatsuta/.rbenv/versions/2.1.5/bin/ruby --with-sqlite3-dir --without-sqlite3-dir --with-sqlite3-include --without-sqlite3-include=${sqlite3-dir}/include --with-sqlite3-lib --without-sqlite3-lib=${sqlite3-dir}/lib /Users/skatsuta/.rbenv/versions/2.1.5/lib/ruby/2.1.0/mkmf.rb:456:in `try_do': The compiler failed to generate an executable file. (RuntimeError) You have to install development tools first. from /Users/skatsuta/.rbenv/versions/2.1.5/lib/ruby/2.1.0/mkmf.rb:587:in `try_cpp' from /Users/skatsuta/.rbenv/versions/2.1.5/lib/ruby/2.1.0/mkmf.rb:1120:in `block in find_header' from /Users/skatsuta/.rbenv/versions/2.1.5/lib/ruby/2.1.0/mkmf.rb:918:in `block in checking_for' from /Users/skatsuta/.rbenv/versions/2.1.5/lib/ruby/2.1.0/mkmf.rb:351:in `block (2 levels) in postpone' from /Users/skatsuta/.rbenv/versions/2.1.5/lib/ruby/2.1.0/mkmf.rb:321:in `open' from /Users/skatsuta/.rbenv/versions/2.1.5/lib/ruby/2.1.0/mkmf.rb:351:in `block in postpone' from /Users/skatsuta/.rbenv/versions/2.1.5/lib/ruby/2.1.0/mkmf.rb:321:in `open' from /Users/skatsuta/.rbenv/versions/2.1.5/lib/ruby/2.1.0/mkmf.rb:347:in `postpone' from /Users/skatsuta/.rbenv/versions/2.1.5/lib/ruby/2.1.0/mkmf.rb:917:in `checking_for' from /Users/skatsuta/.rbenv/versions/2.1.5/lib/ruby/2.1.0/mkmf.rb:1119:in `find_header' from extconf.rb:30:in `<main>'
extconf failed, exit code 1
Gem files will remain installed in /Users/skatsuta/.rbenv/versions/2.1.5/lib/ruby/gems/2.1.0/gems/sqlite3-1.3.10 for inspection. Results logged to /Users/skatsuta/.rbenv/versions/2.1.5/lib/ruby/gems/2.1.0/extensions/x86_64-darwin-14/2.1.0-static/sqlite3-1.3.10/gem_make.out
どうやら Makefile の生成に失敗しているようです。 Check the mkmf.log file for more details. とあるので、 mkmf.log を探してみます。
$ export LIBRARY_PATH=/usr/local/lib:$LIBRARY_PATH $ gem install sqlite3 -v '1.3.10' Fetching: sqlite3-1.3.10.gem (100%) Building native extensions. This could take a while... Successfully installed sqlite3-1.3.10 Parsing documentation for sqlite3-1.3.10 Installing ri documentation for sqlite3-1.3.10 Done installing documentation for sqlite3 after 0 seconds 1 gem installed
Linux 以外の OS 上で Docker を利用する場合、 VirtualBox などで Linux のホスト VM を立てる必要があります。このとき、ホスト VM からローカルへポートフォワーディングしたいと思うときがあります。これをおこなうには、 VirtualBox の CLI である VBoxManage の controlvm コマンドを使います。
$ docker run -e POSTGRES_PASSWORD=password -d -p 5432:5432 postgres fd17b2e20ee3b09bbb446449f4182ad0aea24d2a4f4e8ba1a700c11af6671970 $ docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES fd17b2e20ee3 postgres "/docker-entrypoint.s" Less than a second ago Up 1 seconds 0.0.0.0:5432->5432/tcp serene_varahamihira
このとき、ホスト VM 名が dev であるとすると、ホスト VM の 5432 から ローカルの 5432 にポートフォワーディングするには、以下のコマンドを実行します。
1
$ VBoxManage controlvm dev natpf1 "psql_pf,tcp,127.0.0.1,5432,,5432"