feel free to skip straight to the second course when CS50 (the first course) moves away from C.
という但し書きの通り、 CS50 の Week 5 以降の講義では主題が C から HTML や CSS, JavaScript, Python に変わってしまい、ざっと見た感じ内容もそれまでと比べて易しくなる印象だったので、 Week 5 以降は受講していません。
受講した結論としては、「C 言語を使ってメモリ管理やアルゴリズム、データ構造などを意識しながら小規模のプログラムを書く」という良い経験ができ、そのへんの素養がなかった私にとってはとても良い勉強になりました。あと、 Week 4 の演習内の最後の課題である “speller” というプログラムの実行速度を競う以下のランキングで、いろいろチューニングを頑張った結果現状 3 位にまでランクインすることができた (2018 年 3 月 14 日時点) のも嬉しい事柄でした。
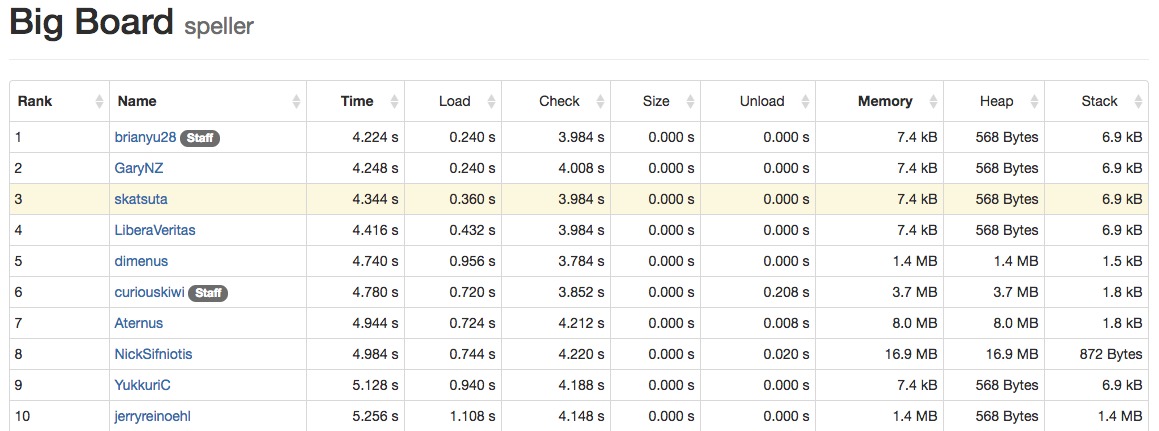
この位置につけるまで結構試行錯誤したので、嬉しくて思わずスクリーンショットを取ってしまいました (でもまだ上がいるんですよね……)。
受けたかった部分の受講は完了し、それなりに満足できる結果も出せて一区切りついたので、 CS50 の Week 1 ~ 4 で学んだ内容をまとめてみようと思います。
CS50’s Introduction to Computer Science について
これは edX というオンラインコースプラットフォーム (いわゆる MOOC) 上で公開されている講座で、 Harvard 大学の CS50 というコンピュータサイエンス入門用の授業がオンラインで公開されているものです。受講するだけならアカウント登録をおこなえば無料で受けられます (これに限らず、 OSSU で紹介されている講座はすべて基本的に無料です。)
この講座に限らずオンライン講座一般のいいところとしては、多くの場合レクチャーのビデオと演習用の課題がセットで用意されており、スムーズに独学できるところだと感じています。
レクチャーはすべて英語ですが、字幕も表示できるのでそれで補足しながらであれば説明されていることは概ね把握できますし、スライドや PC の画面も表示されるので理解の助けになります。かつ、この CS50 の担当教授である David J. Malan 先生の熱量がすごく、たとえば生徒も巻き込んでステージ上でアルゴリズムのイメージを実演してくれるなどしながら、毎回非常にわかりやすく講義内容を説明してくれます。ただし私のように非ネイティブの人にとっては、この人の喋りは勢いがすごくかなり早口に感じると思うので、最初それについていくのが大変かもしれません。
各講義回ごとに演習用の課題が用意されており、実際に課題の要件を満たすプログラムを実装して提出する必要があるのもやっていて楽しい点です。 CS50 では Cloud9 をベースにした CS50 IDE という Web IDE が提供されていて、ブラウザ上でコーディングから課題の提出までおこなえるので、ローカルに開発環境を構築する手間がまったく必要ないのもいいところです。実装結果を提出するとリモートでテストが実行され、要件を満たしているかどうか自動的に評価されるようになっていて、これも素晴らしい点だと思います。
ただし Cloud9 のサーバーがおそらく米国にあるため、日本から使うと IDE のターミナル上でのコマンドの入力に微妙に遅延を感じます (遠い国にあるサーバーに SSH して操作するときに感じるラグと同じ感じ)。なお IDE エディタ上のコーティング作業自体はまったく問題ありません。
Week 1 ~ 4 の講義の内容と学んだこと
コンピュータサイエンスの入門講座のため、とても基礎的な内容ですが、私にとっては良い勉強になりました。特に探索やソートといったアルゴリズムや、 C 言語のメモリ管理、そしてデータ構造の実装について実際に手を動かして学ぶことができました。
演習課題も背景知識や実装方針などが非常に丁寧に説明されていて (動画での解説もある)、初学者でもつまづかないようかなり配慮されているように感じられました。課題の内容も結構おもしろいものが多かったです。
Week 1
何かしらプログラムを書いたことがある立場からすると、 Week 1 の内容は簡単でした。プリミティブなデータ型、演算子、ループ、条件分岐といった、 C 言語の入門として最初に習うものです。
ただし演習課題の1つである Credit という問題で、「クレジットカード番号の単純な認証には Luhn アルゴリズムによるチェックサムが使われている」という背景知識が知れたことは勉強になりました。
レクチャー
- Hello, World
- データタイプ (
int,double, …) - 演算子 (
+,-, …) - ループ (
for,while) - 条件分岐 (
if,switch) - 計算誤差 (桁あふれ、打切り誤差等)
演習課題
- Mario: 入力値に応じた階段状のブロックを表示するプログラムを実装する
- Cash: お釣りの金額に必要な最小のコイン数を計算するプログラムを実装する
- Credit: Luhn アルゴリズムとクレジットカード会社ごとの発行番号の規約から、与えられたクレジットカード番号がどのカード会社のものか判定するプログラムを実装する
演習課題は “less comfortable” と “more comfortable” のうちどちらか 1 つずつをやればいいようになっていましたが、せっかくなので両方やりました。
Week 1, continued
Week 1 の続きの講義もまだまだ初歩的な内容でした。主に文字列と配列に焦点が当たっていました。 C の文字列は非常に原始的で「NUL 文字 \0 で終端された単なる char の配列である」という点は、日頃現代的な言語を利用していると不便さを感じるときもありますよね。
おもしろかったのは Crack という演習課題で、 unistd.h の crypt 関数で暗号化されたパスワードを、ブルートフォースアタックにより解読するという内容でした。
レクチャー
- 文字列と ASCII コード
- 配列
- コマンドライン引数
- 簡単な暗号
演習課題
- Caesar: Caesar 暗号で入力文字列を暗号化するプログラムを実装する
- Vigenère: Vigenère 暗号で入力文字列を暗号化するプログラムを実装する
- Crack: C の
crypt関数で暗号化されたパスワードのハッシュ文字列から、もとのパスワード文字列を見つけ出すプログラムを実装する
上記 3 つ中 2 つを提出すればよいことになっていましたが、せっかくなので 3 つ全部やりました。 Crack の課題では、パスワードはすべてアルファベットで最長でも 5 文字という前提になっており、総当りで解読できるような条件設定になっています。 C で 1 ~ 5 文字の文字列の全組み合わせを生成する処理の実装方法に少し悩んだ記憶があります。
Week 2
Week 2 から私にとってはだんだんおもしろくなってきました。アルゴリズムの勉強の最初に習う探索、ソート、計算量の話です。マージソートの計算量が になる理由がよくわかっていなかったので、ちゃんと理解することができて勉強になりました。ただソートではクイックソートやヒープソートといった、現在主に使われているであろう高速ソートの説明がなかったのが少し残念です。
今回の Music という課題もなかなかおもしろい演習で、「楽譜データを読み込んでその曲の WAV ファイルを生成するプログラムの一部を実装する」というものでした。
レクチャー
- 文字列操作
- 探索
- 線形探索 (linear search)
- 二分探索 (binary search)
- ソート
- バブルソート (bubble sort)
- 選択ソート (selection sort)
- 挿入ソート (insertion sort)
- マージソート (merge sort)
- 計算量
- 記法と 記法
演習課題
- Music: 楽譜データを読み込んでその曲の WAV ファイルを生成するプログラムの一部を実装する
この課題は一部のヘルパー関数を実装するだけで、実装ボリューム自体は全然大したことないのですが、音楽の知識がなかったので背景知識をきちんと把握するまでに手間取りました。あと日本人は音階の表記に「ドレミファソラシ」を使うので、 “CDEFGAB” を使う欧米の表記法との間を脳内で相互変換するのも最初苦労しました。
まずこのプログラムの概要は、楽譜データのテキストファイルを読み込んで、記載された各音符の音階と長さの系列データをもとに、波形データを生成して WAV ファイルとして出力する、というものになっています。
WAV ファイルの生成処理などはライブラリが同梱されており、大部分の処理についてはもともと実装されています。演習で実装するのは、楽譜のテキストデータの各音符の情報を入力として
- 休符かどうか判定する関数
is_rest - 音符の長さを計算する関数
duration - 音符の高さから周波数 (Hz) を計算する関数
frequency
という3つのヘルパー関数だけなので、実装ボリューム自体は大して多くありません。
ですが個人的に難しかったのが frequency の実装です。背景知識を読んでへーと思ったのが、黒鍵の音符には2通りの表記法があるという点でした。たとえばドとレの白鍵の間の黒鍵の音は、ド# ともレbとも表せるということです。なのでどちらの音符であっても、同じ周波数を出力しないといけません。
また、各音符の高さの周波数は「4オクターブめのラ (A4)」の 440 Hz を中心に、そこからの黒鍵を含めた音階の差分をもとに計算します。しかしながら「ミとファ」や「シとド」の間には黒鍵がありません。また、オクターブは「ドレミファソラシド」で一周すると1つ上下します。なので、たとえば「6オクターブめのミ (E6) は基準となる4オクターブめのラ (A4) から何音階分離れているか」といったことをどのように計算すればよいのか結構考えました。
最終的に正しく実装できて、同梱されている楽譜データの「きらきら星」や「ロンドン橋落ちた」、「Jeopardy! のテーマソング」などがちゃんと再生されたときは達成感があり、嬉しかったです。
演習課題としてはおもしろかったのですが、でもこれ探索もソートも計算量も全然関係ない問題なんですよね。なんでこの回の課題がこれなのか不思議です。
Week 3
Week 3 ではメモリ管理やポインタが主題でした。私がよく使う Go 言語だとありがたいことに GC とエスケープ解析があるので、通常各ポインタのオブジェクトがスタックとヒープのどちらに置かれているか意識しないで済んでしまいます。一方 C 言語ではプログラマがちゃんと考えて、スタックにアロケートするかヒープにアロケートするか判断する必要があります。このように自力でメモリ管理をするプログラムを書く経験もやはり大事だなと感じました。
Week 3 の演習課題はすべて Bitmap (BMP) の画像ファイルを扱う内容で、「BMP ファイルのヘッダ情報や画像データのレイアウトはどうなっているのか」といったことを実装を通してよく理解することができるようになっており、これもかなり勉強になる演習でした。 BMP ファイルは他の画像形式と比較すると中身が単純なため、画像ファイルのデータ構造の入門に適していると思います。
レクチャー
- プログラムのメモリレイアウト (text, data, stack, heap)
- 関数とスタック
- ポインタ
mallocとヒープ- 画像データ (Bitmap)
- 構造体
演習課題
- Whodunit: 与えられた BMP ファイルに隠されたメッセージを見つけるプログラムを実装する
- Resize: BMP ファイルをリサイズするプログラムを実装する
- Recover: たくさんの BMP ファイルが1つに連結されたバイナリファイルを読み込んで、それを個別の BMP ファイルに復元するプログラムを実装する
どれも BMP ファイルのヘッダ情報の詳細や画像データのレイアウトをきちんと理解した上で取り組まないとできない課題になっているため、 Bitmap の仕様のドキュメントをかなり読みました。また当然 malloc を使うところもあるので、レクチャーの内容に関連した応用課題にもなっています。
個人的に上記 3 つの中で一番難しかったのが Resize の実装で、入力 BMP 画像をリサイズした結果として、ヘッダ情報と画像データレイアウト (特にパディング) が両方とも適切に変更された画像を生成しないといけません。どこで嵌っていたのか忘れてしまったのですが、これがなかなか正しく実装できず、たとえばニコちゃんマーク画像を拡大しようとしてもグチャグチャな出力画像になってしまったりして、正しい挙動をする実装にたどり着くまでにだいぶ苦労した記憶があります。最終的にちゃんと大きなニコちゃんマーク画像が出力されたときはやったーと思いました。
Week 4
Week 4 は一番勉強になった講義回でした。データ構造はコンピュータサイエンスの基礎知識として非常に重要ですし、特にハッシュテーブルは数あるデータ構造の中でももっとも便利で利用頻度の高いものだと思うので、その実装方法を理解しておくことは大切だと感じました。言語組み込みや標準ライブラリにハッシュテーブルがない C 言語で自力で実装してみると、「ハッシュテーブルはリンクリストの配列により実装できる」ということがよく理解できますし、バケット数とエントリ数の比率であるロードファクターという指標がなぜ重要なのかも具体的にわかります。また、検索が確実に でおこなえるトライ木も、その有用さがわかりました。
今回の演習課題がこれまでで一番やりがいのあるものでした。プログラムの実行速度を競えるランキングがあるので、いろいろ試行錯誤しながらタイムを短縮していく楽しみがありました。
レクチャー
- 構造体
- コールスタック
- スタックオーバーフロー
- バッファオーバーフロー
- Valgrind
- データ構造
- リンクリスト
- スタック
- キュー
- ツリー
- ハッシュテーブル
- トライ木
演習課題
- Speller: あらかじめ辞書データを読み込んだ上で、文章が書かれたテキストファイルの各単語を逐次読み込んでいき、それが辞書に載っているかどうか判定して載っていない場合には出力するプログラムの一部を実装する
これがこの記事の冒頭で述べていた演習課題です。プログラムの大枠はあらかじめ実装されており、演習として実装する部分は以下の4つの関数です。
- 辞書データを読み込む関数
load - ある単語が辞書に含まれているかチェックする関数
check - 辞書内の単語の総数を返す関数
size - 辞書データをアンロードする関数
unload
プログラムの流れとしては、 load 関数で辞書ファイルを読み込んで内部で適切なデータ構造 (ハッシュテーブルやトライ木など) として保持したあと、文章ファイルを単語単位で読み込んでいき、それが辞書データに含まれている単語か否かを check 関数で判別していくという流れです。最後の unload 関数は malloc したデータを適切に解放する処理をおこなうステップで、ヒープにアロケートしたオブジェクトをここですべてきちんと free しないと、 Valgrind によるメモリリークチェックで怒られてしまいます。
そしてプログラム内でそれぞれの関数の処理にかかった時間が計測されるようになっており、それを如何に縮められるかが頭の使いどころになっています。辞書データの保持方法として「ハッシュテーブルを使った実装方法」と「トライ木を使った実装方法」がそれぞれ説明されている非常に丁寧な解説動画が用意されているため、要件を満たす各関数を実装すること自体はそれほど苦労せずにおこなえます。しかしながら、単にそれに沿った実装をしただけだとあまり速度は出ません。
この演習課題のおもしろいところは、以下のように実行速度のランキングが集計されて公開されており (誰でも見られます)、生徒同士 (とコーススタッフ) で自分が実装したプログラムのタイムを競えるようになっているところです。2018 年 3 月 14 日時点で 330 名以上がエントリしています。
私の場合、一番最初の実装ではたしか 20 ~ 30 位の間ぐらいだったと思います。その後いろいろと試行錯誤しながら実行速度の改善を重ねていき、運の良さもありましたが最終的には現時点で 3 位にランクインするタイムを出すことができました。これを通じてパフォーマンスチューニングという観点での学びがたくさんあり、非常に勉強になりました。今回はもう記事が長くなってしまったので細かい話は書きませんが、今後また別の記事でこの演習において自分がやったことの詳細を書くかもしれません (ただしこの演習課題に特化した話をしても誰のためにもならないと思うので、一般的な話に汎化したいとは思います)。
実際のところ私よりも上位のランカーがまだいるわけなので、まだ最適化の余地は残されているんだろうとは思っていますが、今の私の知識や技術ではこれ以上の改善は難しい状況なので、いつかまた修行を積んでから再度挑戦できたらいいなと思います。このランキングの参加者は基本的に初学者のはずで、演習課題の実装内容自体も簡素なものなので、おそらく速度に気を使って C / C++ 言語を長い間書いてきたプログラマの方であれば、私よりも全然速いプログラムを書ける可能性がかなり高いと思っています。なのでもしこの記事を読んで興味が沸いた方は、この演習だけでもやってみるとおもしろいかもしれません。
勉強の方法の 1 つとしてオンラインコースはおすすめかも
何かを勉強する方法として、良質なオンラインコースがあるようであれば、それをやってみるのは 1 つの方法としてありだなーと感じました。もちろん書籍を読んだりするほうが勉強効率としては桁違いに良いはずで、それで進められるのが理想的だと思います。オンラインコースは時間がかかる割にはあまり多くのことを学ぶことはできないでしょう。しかしながら演習課題があって自分で手を動かし、しかもその結果がすぐに評価される仕組みの上で取り組むと、ゲーミフィケーション的な効果で自分が積極的に参加している感じになり、モチベーションを高く維持することができるなと感じました。特に基礎的・入門的な内容の勉強にはオンラインコースは 1 つの選択肢としてありなのではないかと思います。
あと個人的に良かった副作用として、 C 言語が結構好きになりました。日頃現代的な言語を使っていると古臭い言語に感じることは確かで、実際不便な点やバグを生みやすい点も数多くありますが、この素朴さは特に低レイヤのプログラムを書くのにはやっぱり使いやすいんだろうなと思います。今となっては C でも Go でも問題なくポインタを扱うことができるようになっていますが、実は昔 C のポインタで一度挫折した経験があったので、それを無事克服することができてよかったです。
OSSU のカリキュラムに従い、次は Introduction to Computer Science and Programming Using Python という MIT のオンラインコースを受講しています。これまで Python はほとんど書いたことがありませんでしたが、書いてみるとこれも非常に使いやすい言語で、人気の理由がよくわかります。また一区切りついたらレポートを書くかもしれません。
引き続き日々精進していこうと思います。
]]>